
티스토리 뷰
지난번에 했던 캐글 타이타닉 데이터 분석 - 1 https://jfun.tistory.com/136 에 이어 블로깅하려고 한다.
타이타닉 데이터를 다시 불러오자
import pandas as pd
train = pd.read_csv('titanic/train.csv')
test = pd.read_csv('titanic/test.csv')
오늘 하려는 주제는 지난번 데이터를 feature engineering 하는 것인데 이 과정은 상당히 중요하다. 이 부분을 제대로 하지 못하면 어떤 classifier를 사용하더라도 좋은 예측을 할 수 없다.
4. Feature engineering¶
Feature Engineering은 데이터에 대한 도메인 지식을 사용하여 기계 학습 알고리즘을 작동시키는 Feature(Feature vectors)를 만드는 과정이다.
feature vector는 어떤 object를 나타내는 숫자 형상의 n차원 벡터다. 머신 러닝에 있어 많은 알고리즘은 object들의 수치적 표현을 필요로 한다. 왜냐하면 그러한 표현은 컴퓨터 입장에서 처리와 통계 분석을 용이하게 하기 때문이다.
train.head()
4.1 어떻게 타이타닉은 가라앉았나?¶
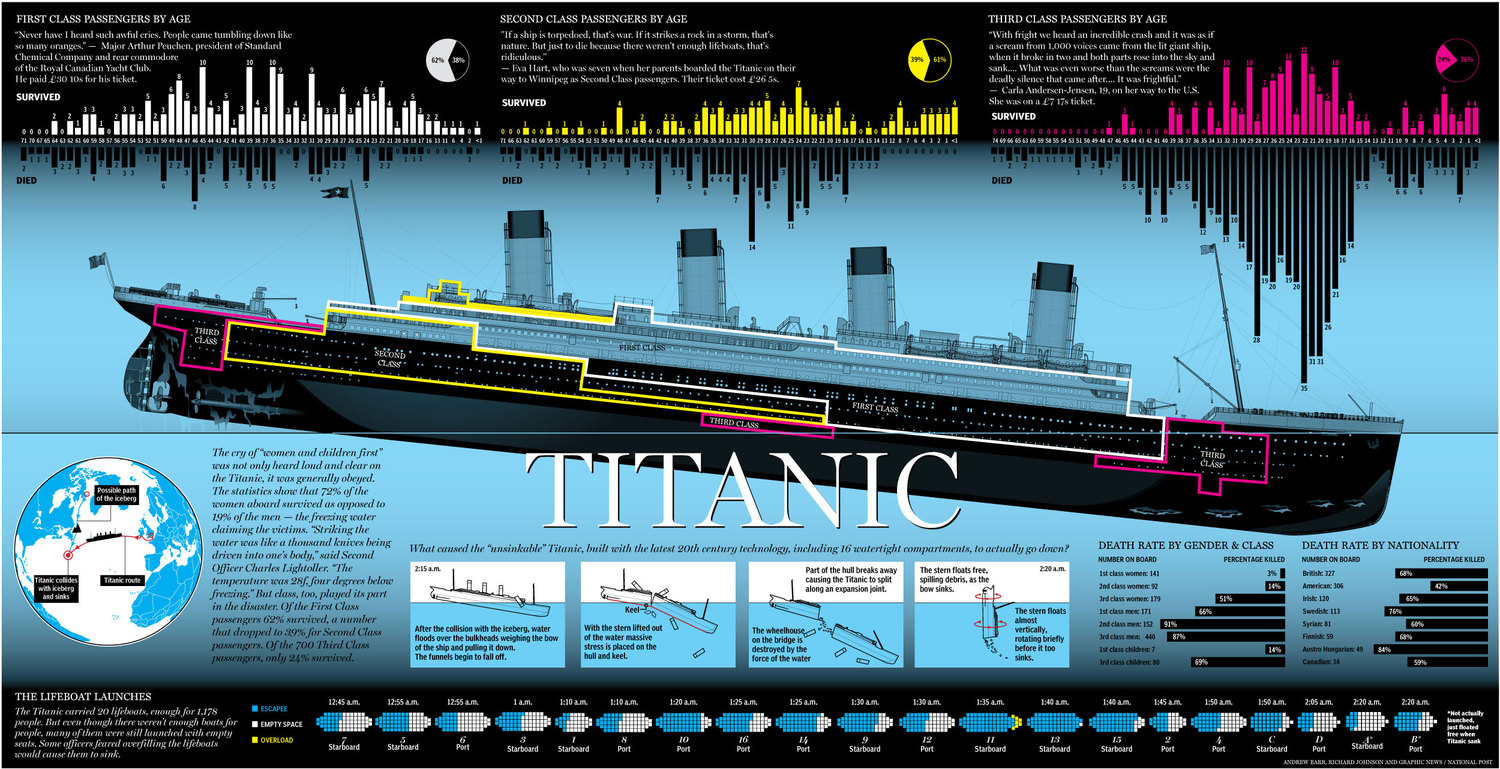
타이타닉이 어떻게 바닷속에 들어갔을까? 위 그림에서 타이타닉의 머릿부분인 오른쪽 뱃머리가 빙하에 부딧히면서 바다에 잠기게 된다. 그러면서 그 부분에 있던 3등급 칸이 가장 먼저 잠기면서 사람들이 많이 죽게 되었다. 반면 반대쪽 3등급 칸은 시간이 더 있었을테니 살아남을 가능성이 더 있었을 것이다. 그리고 1,2등급은 생존하기에 더 좋은 위치이다. 그렇기 때문에 티켓의 등급은 생존 유무를 구하는 좋은 변수이다.
train.head(10)
제일 먼저 볼 feature는 name이다. name에 따라서 사람이 죽었다 살았다 판단하지는 못할 것이다. 그렇지만 남성과 여성을 나타내는 Mr., Miss, Mrs. 와 같은 중요한 정보가 있다. 이름에서 이 타이틀 들을 빼 내고 이름 항목을 삭제할 것이다.
4.2 Name¶
train_test_data = [train, test] #훈련 및 시험 데이터 세트 결합
for dataset in train_test_data:
dataset['Title'] = dataset['Name'].str.extract('([A-za-z]+)\.', expand=False)
이름에서 Mr., Miss., Mrs.만 빼 내겠다
train['Title'].value_counts()
test['Title'].value_counts()
각 호칭을 숫자에 매핑 시키자.
위에서 훈련 및 시험 데이터 세트를 결합했기 때문에 두 데이터 세트를 한번에 바꿔줄 수 있다.
Title map
Mr: 0
Miss: 1
Mrs: 2
Others: 3
title_mapping = {"Mr":0, "Miss":1, "Mrs":2,
"Master":3, "Dr":3, "Rev":3, "Col": 3, 'Ms': 3, 'Mlle': 3, "Major": 3, 'Lady': 3, 'Capt': 3,
'Sir': 3, 'Don': 3, 'Mme':3, 'Jonkheer': 3, 'Countess': 3 }
for dataset in train_test_data:
dataset['Title'] = dataset['Title'].map(title_mapping)
train.head()
살았는지 죽었는지 두개의 막대차트로 표시하는 '캐글 타이타닉 데이터 분석 - 1' 에서 정의했던 함수.
def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Survived','Dead']
df.plot(kind='bar',stacked=True, figsize=(10,5))
bar_chart('Title')

0번 Mr.(남성)은 상대적으로 많이 죽었음을 알 수 있다. 반면 1번과 2번 Miss와 Mrs.(여성)은 상대적으로 많이 생존했음을 알 수 있다.
데이터에서 Name에 대한 항목은 필요없으므로 train과 test dataset에서 삭제해주자.
# 데이터 셋에서 불필요한 feature 삭제
train. drop('Name', axis=1, inplace=True)
test.drop('Name', axis=1, inplace=True)
train.head()
4.3 Sex¶
male: 0 female:1
남자인지 연자인지 이미 명확히 구분되어 있는 정보로 텍스트를 숫자로만 변환시켜 주겠다.
sex_mapping = {"male": 0, "female":1}
for dataset in train_test_data:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)
bar_chart('Sex')

4.4 Age¶
다음 나이인데 여기서 주의할 점은 중간중간에 빠진 정보가 존재한다는 사실이다.
이런 missing information에 대해서는 과학적인 방법을 이용해서 채워줘야 한다.
가장 기본적인 생각으로는 나머지 모든 사람의 나이의 평균을 구해 채워주는 방법이다.
그러나 조금더 과학적인 방법으로 접근해보고 싶다.
위에서 구했던 Title에서 남성끼리 평균나이 Mr.끼리 평균나이 Miss끼리 평균나이를 구해서 채워주면 전체 평균을 구해 채워주는 방법보다 더 나을 것이다.
# Missing Age를 각 Title에 대한 연령의 중간값 으로 채운다(Mr, Mrs, Miss, Others)
train['Age'].fillna(train.groupby('Title')['Age'].transform('median'), inplace=True)
test['Age'].fillna(test.groupby('Title')['Age'].transform('median'), inplace=True)
import matplotlib.pyplot as plt
import seaborn as sns
facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
sns.axes_style("darkgrid")
plt.show()

10대 중반 정도까지는 생존률이 높고 30대 부근과 70대 근처의 노인분들의 사망률이 높다는 것을 알 수 있다.
나이대별로 잘라서 그래프를 확대 출력해서 자세히 보도록 하자.
facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlim(0,20)
plt.style.use('ggplot')

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlim(20,30)

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlim(30,40)

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlim(40,60)

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Age', shade=True)
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
plt.xlim(60)

train.info()
test.info()
나이를 그대로 그래프 차트에 넣으면 0살부터 80살까지 너무 많은 정보가 들어있다. 그래서 feature engineering에서 Binning이라는 기술이 있는데, 이렇게 잇달아 일어나는 형태의 데이터는 많은 정보를 주지 못하므로 이럴땐 각각 하나의 카테고리에 나이를 담아 정보를 보다 명확하게 확인할 수 있는 방법이다.
for dataset in train_test_data:
dataset.loc[ dataset['Age'] <=16, 'Age']=0,
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <=26), 'Age'] = 1,
dataset.loc[(dataset['Age'] > 26) & (dataset['Age'] <=36), 'Age'] = 2,
dataset.loc[(dataset['Age'] > 36) & (dataset['Age'] <=62), 'Age'] = 3,
dataset.loc[(dataset['Age'] > 62), 'Age'] = 4
train.head()
bar_chart('Age')

0에 해당하는 16세 아이들의 경우 다른 그룹보다 생존률이 높음을 확인할 수 있다. 4에 해당하는 62세 이상의 어르신들은 사망률이 아주 높다는 것을 확인할 수 있다. 이렇게 Age information을 binning이라는 테크닉을 이용하여 좀 더 이해하기 쉽게 그래프로 보일 수 있고, classifier 하는데 조금 더 쉽게 예측할 수 있다.
4.5 Embarked¶
4.5.1 filling missing values¶
도시별로 부유한 사람과 가난한 사람의 비율의 차이가 있지 않을까?
Pclass1 = train[train['Pclass']==1]['Embarked'].value_counts()
Pclass2 = train[train['Pclass']==2]['Embarked'].value_counts()
Pclass3 = train[train['Pclass']==3]['Embarked'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class', '2nd class', '3rd class']
df.plot(kind='bar', stacked=True, figsize=(10,5))

Q 도시에서 탄 사람들은 1등급이 거의 없다. S 도시에서 탑승한 사람들이 대부분을 차지하고 있다. 즉, Embarked 정보가 쓰여있지 않다면 S라고 써도 무방할 것 같다.
Embarked 정보가 없으면 S를 집어넣자
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
train.head()
그리고 머신러닝 classifier를 위해 텍스트를 숫자로 바꿔주자.
embarked_mapping = {'S':0, 'C':1, 'Q':2}
for dataset in train_test_data:
dataset['Embarked'] = dataset['Embarked'].map(embarked_mapping)
4.6 Fare¶
티켓 가격이 안채워져 있을때는 어떻게 채울 수 있을까?
티켓 가격은 클래스과 관련이 높다. 그리고 클래스는 missing value가 존재하지 않았다. 그러므로 각 클래스의 티켓 가격 가운데 값을 티켓 가격의 missing value에 넣어주겠다.
train["Fare"].fillna(train.groupby('Pclass')['Fare'].transform('median'), inplace=True)
test["Fare"].fillna(test.groupby('Pclass')['Fare'].transform('median'), inplace=True)
facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Fare', shade=True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.show()

싼 티켓을 구매한 사람은 사망률이 높고 비싼 티켓을 구매한 사람은 생존률이 높다는 것을 알 수 있다.
facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Fare', shade=True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.xlim(0,20)

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Fare', shade=True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.xlim(0,30)

facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'Fare', shade=True)
facet.set(xlim=(0, train['Fare'].max()))
facet.add_legend()
plt.xlim(0) # 티켓의 개수가 0이 되는 티켓의 가격
binning을 사용하여 각 구간별로 티켓 가격을 카테고리에 넣어주자.
for dataset in train_test_data:
dataset.loc[ dataset['Fare'] <=17, 'Fare'] = 0,
dataset.loc[(dataset['Fare'] > 17) & (dataset['Fare'] <=30), 'Fare'] = 1,
dataset.loc[(dataset['Fare'] > 30) & (dataset['Fare'] <=100), 'Fare'] = 2,
dataset.loc[ dataset['Fare'] > 100, 'Fare'] = 3,
train.head()
4.7 Cabin¶
train.Cabin.value_counts()
알파벳으로 시작하고 숫자가 나오는 형태를 띠고 있다. 숫자는 핸들링 하기 어려워서 캐릭터만 가지고 해보자.
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].str[:1]
Pclass1 = train[train['Pclass']==1]['Cabin'].value_counts()
Pclass2 = train[train['Pclass']==2]['Cabin'].value_counts()
Pclass3 = train[train['Pclass']==3]['Cabin'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class', '2nd class', '3rd class']
df.plot(kind='bar', stacked=True, figsize=(10,5))

1등급에는 ABCDET, 2등급에는 DEF, 3등급은 EFG로 구성되어 있다.
이것을 classifier를 위해 매핑시켜주자.
cabin_mapping = {'A':0, 'B':0.4, 'C':0.8, 'D':1.2, 'E':1.6, 'F':2, 'G':2.4, 'T': 2.8}
for dataset in train_test_data:
dataset['Cabin'] = dataset['Cabin'].map(cabin_mapping)
소수점을 사용하는 이 방법을 feature scaling이라고 하는데, 머신러닝 classifier는 숫자를 사용하고 계산을 할 때 보통 euclidean distance를 사용한다. 숫자의 범위가 비슷하지 않으면 큰 거리에 있는 것을 조금 더 중요하게 생각할 수 있다. 예를들면 남자와 여자는 0과 1로 구분해 놨는데 Fare가 10달러와 20달러 티켓이 있다면 이것은 3등급으로 같다. 남자와 여자의 차이는 1이고 10달러와 20달러의 차이는 10이니깐 우리가 같은 range를 주지 않을 경우 머신러닝 classifier는 남자와 여자의 차이보다 요금의 차이를 크게 인식한다. 그래서 범위를 비슷하게 주기 위해서 소수점을 사용했다. 라고 설명을 들었는데 행렬형태로 주는게 조금 더 낫지 않을까?
Cabin의 missing field는 1등급 2등급 3등급 클래스와 밀접한 관계가 있기 때문에 각 클래스별 cabin의 중간값을 missing value에 넣어주도록 한다.
train['Cabin'].fillna(train.groupby('Pclass')['Cabin'].transform('median'), inplace=True)
test['Cabin'].fillna(test.groupby('Pclass')['Cabin'].transform('median'), inplace=True)
4.8 FamilySize¶
함께 동승한 부모님과 아이들의 수와 형제와 배우자의 수의 사망률에 대해 관계가 유사하였고, 궁금한 점은 혼자 탔는지 함께 탔는지가 궁금하기때문에 SibSb 데이터와 Parch 데이터를 합쳐 하나의 값을 만드는 것도 괜찮을 것 같다.
train['FamilySize'] = train['SibSp'] + train['Parch'] + 1
test['FamilySize'] = test['SibSp'] + test['Parch'] + 1
facet = sns.FacetGrid(train, hue="Survived", aspect=4)
facet.map(sns.kdeplot, 'FamilySize', shade=True)
facet.set(xlim=(0, train['FamilySize'].max()))
facet.add_legend()

혼자 탔을경우 상당히 많이 죽었음을 알 수 있다. 반면 가족이 한명이라도 있을경우 사망률이 많이 줄어들었다는 것을 확인할 수 있다.
이 정보들도 숫자에 mapping해서 넣어주자.
family_mapping = {1: 0, 2: 0.4, 3: 0.8, 4: 1.2, 5: 1.6, 6: 2, 7: 2.4, 8: 2.8, 9: 3.2, 10: 3.6, 11: 4}
for dataset in train_test_data:
dataset['FamilySize'] = dataset['FamilySize'].map(family_mapping)
train.head()
Ticket 데이터와 SibSp와 Parch는 필요한 정보가 아니므로 빼 주자.
features_drop = ['Ticket', 'SibSp', 'Parch']
train = train.drop(features_drop, axis=1)
test = test.drop(features_drop, axis=1)
train = train.drop(['PassengerId'], axis=1)
train_data = train.drop('Survived', axis=1)
target = train['Survived']
train_data.shape, target.shape
train_data.head(10)
이렇게 숫자로 표현된 정보로 모두 표현해 놓으면, 우리는 머신러닝 classifier를 통해서 prediction 할 수 있다.
출처: https://youtu.be/aqp_9HV58Ls 강의영상을 보면서 제작하였습니다.
'beginner > 파이썬 분석' 카테고리의 다른 글
| 맥주 추천시스템-데이터분할 (0) | 2019.04.23 |
|---|---|
| 맥주데이터 추천시스템_4/22 (0) | 2019.04.22 |
| 캐글 타이타닉 데이터 분석 - 1 (0) | 2019.04.11 |
| Pandas를 이용한 지하철 데이터 분석 (0) | 2019.03.12 |
| 분석 -1 (0) | 2019.03.06 |