
티스토리 뷰
출처 : https://youtu.be/HoT2TheIlUQ
Session1 내용

Session2는 위 그림에서 왼쪽 부분을 다룬다.
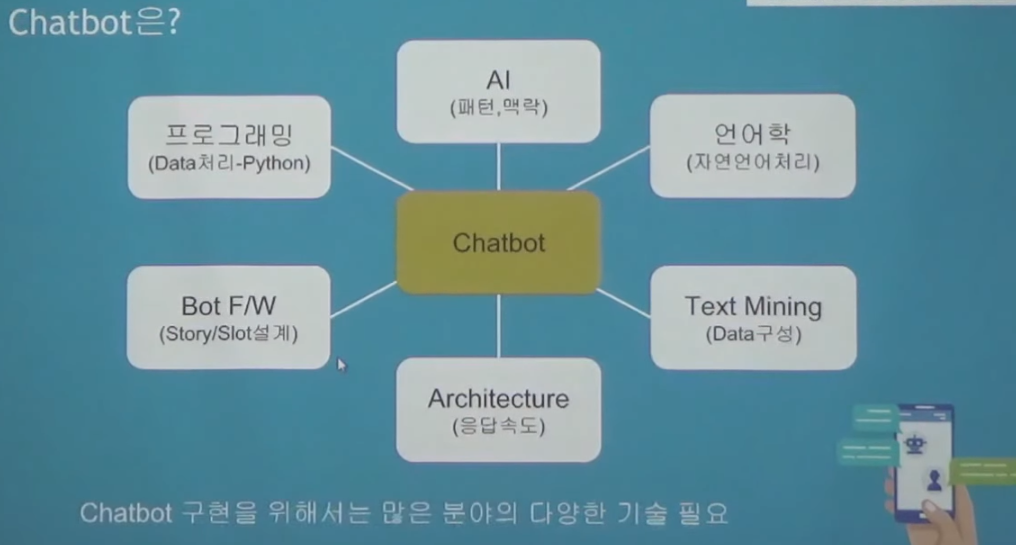
Chatbot의 특징
- 많은 기술이 필요(NLP, AI, F/W, Text Mining and 다양한 개발 skill)
- Deep Learning을 공부하는 입장에서 결과 확인이 빠름
적은 computing으로 빠른 결과확인 가능(Text기반)
- 재미가 있음(Micro Data처리에 비해 Biz dependency가 적은편)
이미지(CNN)이나 정형Data(CNN)보다는 Data처리에 대한 부담감이 적음(형태소 분석기등으로 쉽게 전처리 쓴다는 가정하에)
- 응용분야가 많은 (API기반의 다양한 서비스 연결 Smart Management)
intent와 slot만 채워주면 어느 서비스와 연결가능
- 관련 오픈 소스가 적어 블루오션(우리는 영어인데.. 충분할 듯?)
다행인건 딥러닝 기반의 언어독립적 Text algorithm이 많이 공개되어 활용 가능
- Bot Service가 있으나 가격부담, customize가 불가
다양한 chatbot platform이 존재하고 있다. 이것을 통해서 원하는 서비스를 어느정도 할 수 있다.
모든 챗봇에는 의도(intent)와 개체인식(entity)이 존재하며, 또한 그것을 위해서는 Data가 중요하다.
entity에는 스토리를 이어가기 위한 필수 entity와 엑스트라 entity로 분류할 수 있다.

보통 intent가 100개정도 된다. 딥러닝을 아직까지 잘 사용하지는 않음. 머신러닝을 쓰면서도 기존 Rule이나 핵심키워드를 통해 그로우(?)인텐트는 걸러내야 한다.

고객들이 치는 문장들을 통해서 데이터를 추가.
나만의 챗봇을 만들어보자.
피자 주문 챗봇은 어떻게 만들까?
피자를 주문하려면 피자 종류도 여러가지고, 사이즈도 다양하고, 장소와 날짜, 사이드메뉴 등도 다양한데 어떻게 챗봇으로 만들 수 있을까?
>피자주문과 관련된 스토리지가 구성되어야 함.
>딥러닝과 적당한 로직으로 피자 주문 bot을 만들어보자

1234 과정을 돌면서 채팅을 하는 것이다.
1. 피자 주문해줘
2. 챗봇 서버로 내용이 들어옴
3. 자연어 처리, entity파악
4. 해당 context와 분리하여 의사결정 massaging flatform으로 갈 것인지에 대한 말을 만들어서 던져(필요에 따라서 NLG server를 거쳐)주거나 아니면 주문이 완료되었다는 창이 뜨겠지.
시나리오는 모두 DM server에서 처리 및 판단.

service manager에서 api를 통해 주문할 수 있도록.


맥북 프로라고 검색하더라도 전처리가 들어가야 한다. NER에서 entity를 뽑아냈다고 하더라도 전처리를 통해 대표 Entity가 나와야만 한다.
위 예제의 특징은 사용자는 정해진 프레임안에서 챗봇을 진행한다는 것이다.
챗봇을 어떻게 오픈소스와 파이썬 텐서플로우를 사용하여 서비스를 할 것인가?

Train을 위한 Word Representation
Word Representation의 정의 (컴퓨터가 잘 이해할 수 있게)
- One Hot은 단어별 강한 신호적 특성으로 Train에 효과적 (Scope가 작을경우 -sparse)
- Word단위 Embedding은 단어를 잘 기억한다. (But Sparse) / W2V (유사도)
-Gloves는 단어의 세부 종류까지도 구분 (카라칼-고양이)
-char 단위 embedding은 미훈련 단어 처리에 용이 (Vector을 줄이기 위한 영어변환)
-한글을 변환한 영어 char단위 embedding는 벡터 수를 줄이면서 영어 처리도 가능
Embedding된 데이터를 어떻게 얻는가?
-일반적으로 Biz에 따른 Text는 존재하나 Deep Learning를 구현하기 위해서는 정제된 Text와 Tagging이 가능한 매우 많은 Data가 있어야 한다.
-추가적인 Biz 어휘는 새로 학습시켜야 한다.(노가다).
-Domain Specific의 경우엔 Text Data는 직접 만들어야 한다.(Augmentation)
-특화된 단어의 경우에도 새로 학습시켜야함(ㅎㅇ?, 방가방가)
-고유명사등 새로운 어휘가 생성될때 새로 등록을 해주어야 한다.
학습시킬 데이터의 구성
Train Vector를 정한 후 Feature를 뽑아야 한다.
Cleansing > Feature Engineering > Train
(Cleansing: 상황별 특수문자 제거, Feature Engineering: 의미 있는 단어 도출 - Tagging해서 학습시키기)
의도나 객체와 상관있는 단어만 추출해 내어 성능을 향상시킴.
Train Cost를 줄이고 모델의 성능을 향상
Embedding 차원도 줄이는 효과(SVD)
a~z, 0~9, ?,!, (,)등 약 70여개.
lower를 사용하여 벡터 줄이기
다음은 embedding 차원이 커질수록 sparse해짐을 보여주는 표.
우리는 보다 dense한 결과를 원한다.

1. Chatbot slot
챗봇 만들기
|
input_data = '판교에 지금 주문해줘 output_data = ' '
request = { "intent_id" : " ", "input_data" : input_data, "request_type" : "text" "story_slot_entity" : {} "output_data" : output_Data } |
기본 데이터 셋(DB)
|
intent_list = { "주문" : ["주문", "배달"] "예약" : ["예약", "잡아줘"] "정보" : ["정보", "알려"] }
story_slot_entity = {"주문" : {"메뉴" : None, "장소" : None, "날짜" : None}, "예약" : {"장소" : None, "날짜" : None}, "정보" : {"대상" : None} } |
형태소 분석
|
from konlpy tag import Mecab mecab = Mecab("경로/mecab-ko-dic") preprocessed = mecab.pos(request.get('input_data))
print(preprocessed) |
[('판교', 'NNG'), ('에', 'JKB'), ('지금', 'NNG'), ('피자', 'NNG'), ('주문', 'NNG'), ('해', 'XSV+EC'), ('줘', 'VX+EC')]
Intent 도출(Rule Based) # Char CNN을 사용해서 연결하면 좀 더 쉽게 만들 수 있어
|
intent_id = '주문' slot_value = story_slot_entity.get('주문') |
NER 도출 (Rule Based) # LSTM 기법을 사용해서 연결하면 좀 더 쉽게 만들 수 있어
|
menu_list = ['피자', '햄버거', '치킨'] loc_list = ['판교', '야탑', '서현'] date_list = ['지금', '내일', '모레'] |
Dictionary 기반 slot 구성
|
for pos_tag in preprocessed : if pos_tag[i] in ['NNG', 'NNP', 'SL', 'MAG'] : if pos_tag[0] in menu_list : slot_vlaue['메뉴'] = pos_tag[0] elif pos_tag[0] in loc_list : slot_value['장소'] = pos_tag[0] elif pos_tag[0] in date_list : slot_value['날짜'] = pos_tag[0]
print(story_slot_entity.get('주문')) |
{'날짜', '지금', '장소', '판교', '메뉴', 'None'}
빈 slot 검색
|
if (None in slot_vlaue.values()): key_values = " " for key in slot_value keys() if(slot_value(key) is None) key_values = key_values + key + " " output_data = key_values + "선택해주세요" else: output_data = "주문이 완료 되었습니다."
print(output_data) |
메뉴 선택해주세요.
위에 빈 slot이 채워진다면 '주문이 완료 되었습니다.'라는 메시지가 나온다.
|
response = { "intent_id" : " ", "input_data" : input_data, "request_type" : "text", "story_slot_entity" : {}, "output_data" : " " } response["output_data"] = output_data
print(response["output_data"]) |
메뉴 선택해주세요
마찬가지.
2. Word Representation
One Hot Vector를 통한 출력
|
form konlpy tag import Mecab ona_data = { [ '안녕', '만나서 반가워'], ['넌 누구니', ' 나는 AI봇이란다.'], ['피자 주문 할게', '음료도 주문해줘'], ['음료는 뭘로', '콜라로 해줘'] } mecab = Mecab('경로/mecab-ko-dic') train_Data = list(map(lambda x : mecab.morphs(' '.join(x)), ona_data))
import itertools train_data = list(itertools.chain.from_iterable(train_data))
print(list(train_data)) |
[ '안녕', '만나', '서', '반가워', '넌', '누구', '니', '나', '는', 'AI', '봇', '이', '란다', '.', '피자', '주문', '할게', '음료', '도', '주문', '해', '줘', '음료', '는', '뭘', '로', '콜라', '로', '해', '줘']
|
import numpy as np bucket = np.zeros(len(train_data), dtype = np.float)
for word in train_data : bucket_temp = bucket.copy() np.out(bucket_temp, train_data.index(word), 1) print(bucket_temp) |
[ 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
....
Word to Vector (By Gensim)
W2V를 통해 출력해보자
|
from gensim.models import word2vec
train_data = [train_data] |
[['안녕', '만나', '서', '반가워', '넌', '누구', '니', '나', '는', 'AI', '봇', '이', '란다', '.', '피자', '주문', '할께', '음료', '도', '주문', '해', '줘', '음료', '는', '멀', '로', '콜라', '로', '해', '줘']] model check : Word2Vec(vocab=24, size=50, alpha=0.025)
|
import os file_path = './model' |
model load check : Word2Vec(vocab=24, size=50, alpha=0.025)
| X = model[vocab] print(model.wv.index2word) |
['음료', '줘', '해', '는', '주문', '로', '서', '.', '나', '만나', '니', '반가워', 'AI', '봇', '이', '넌', '할께', '안녕', '란다', '누구', '콜라', '피자', '도', '멀']
안녕, AI등 값의 Vector값 출력
| print(model['안녕']) |
[ 7.70578021e-03 -5.53146517e-03 -6.92201126e-03 -2.27350509e-03 -7.25358166e-03 -3.65838991e-03 8.86415318e-03 2.15791957e-03 1.30950264e-03 7.31933815e-03 -1.18540879e-03 -9.31307487e-03 6.56629913e-04 -2.58653285e-03 4.41709626e-03 2.39771931e-03 -7.02373823e-03 6.34479802e-03 7.52461329e-03 -8.82939436e-03 -9.02117789e-03 7.92329479e-03 7.50020699e-05 4.99623548e-03 5.54782385e-03 -1.45250314e-03 2.13032239e-03 -9.50409472e-03 -5.05588809e-03 -3.81429726e-03 -4.80848877e-03 -3.96375963e-03 7.98807200e-03 4.49646311e-03 -5.40447468e-03 1.51464040e-03 2.80768843e-03 2.68139155e-03 2.86319805e-03 -4.66718478e-03 -9.39708855e-03 8.22522503e-04 8.19624774e-03 -1.39889913e-03 -1.40531920e-04 -8.96323472e-03 6.94040488e-03 -2.65200855e-03 5.67782810e-03 -5.60363103e-03]
| print(model['AI']) |
[ 0.00686154 0.00361068 0.00741995 0.00170702 -0.00885591 0.00929839 0.00695414 0.00986024 -0.00857869 -0.0059921 0.00883905 0.00743784 0.00091376 0.0012838 -0.00613861 -0.00601931 0.00947428 -0.0049699 0.00472253 0.00368309 -0.00909072 0.00296947 0.00167912 0.00073072 0.00299315 -0.00926693 0.00218145 0.00569272 0.00465171 0.00474436 -0.00436316 -0.0057118 0.00066927 -0.00694768 0.00813383 -0.00635307 0.00345884 -0.00908514 -0.00155862 0.00322275 -0.0075618 0.00798893 0.006153 -0.0021826 0.00152068 -0.00950876 -0.0058475 0.00594261 0.00286639 -0.0001673 ]
| result1 = model.most_similar(positive='누구', negative='', topn=10) print(result1) |
[('멀', 0.3275527358055115), ('AI', 0.2745295464992523), ('나', 0.2217162847518921), ('만나', 0.218133807182312), ('할께', 0.1292283535003662), ('음료', 0.08259749412536621), ('도', 0.08101271837949753), ('는', 0.06811986863613129), ('해', 0.05928724631667137), ('이', 0.05255215987563133)]
| from sklearn.manifold import TSNE import pandas as pd import matplotlib import matplotlib.pyplot as plt font_name = matplotlib.font_manager.FontProperties( fname="/usr/share/fonts/truetype/nanum/NanumGothic.ttf" # 한글 폰트 위치를 넣어주세요 ).get_name() vocab = model.wv.index2word matplotlib.rc('font', family=font_name) tsne = TSNE(n_components=2) X_tsne = tsne.fit_transform(X) #t-분포 확률적 임베딩(t-SNE)은 데이터의 차원 축소에 사용 df = pd.concat([pd.DataFrame(X_tsne), pd.Series(vocab)], axis=1) df.columns = ['x', 'y', 'word'] fig = plt.figure() ax = fig.add_subplot(1, 1, 1) print(df) ax.scatter(df['x'], df['y']) ax.set_xlim(df['x'].max(), df['x'].min()) ax.set_ylim(df['y'].max(), df['y'].min()) for i, txt in enumerate(df['word']): ax.annotate(txt, (df['x'].iloc[i], df['y'].iloc[i])) plt.show() |
x y word
0 -0.000014 0.000128 음료
1 -0.000102 -0.000018 줘
2 -0.000098 -0.000030 해
3 -0.000156 -0.000074 는
4 -0.000023 -0.000035 주문
5 0.000140 -0.000050 로
6 -0.000157 -0.000004 서
7 0.000093 0.000073 .
8 0.000018 0.000022 나
9 -0.000111 -0.000008 만나
10 -0.000099 0.000034 니
11 -0.000150 0.000047 반가워
12 0.000047 0.000060 AI
13 0.000040 0.000027 봇
14 -0.000044 0.000077 이
15 0.000175 0.000020 넌
16 -0.000127 -0.000007 할께
17 -0.000054 -0.000007 안녕
18 0.000006 -0.000124 란다
19 0.000017 0.000025 누구
20 -0.000151 0.000064 콜라
21 -0.000071 0.000076 피자
22 -0.000109 -0.000131 도
23 0.000145 -0.000087 멀

딥러닝 하고 싶을때

1. 의도를 파악하는 부분

여기서는 의도가 '주문' 이었다.
딥러닝 효과를 늘리기 위해 Pattern Generation에서 양을 불린다.
2. NER, 즉 entity를 어떻게 뽑을까?

여기서는 '판교', '오늘', '피자'와 같이 각 entity들을 뽑아낼 수 있어야 한다.
'판교', '오늘', '피자'가 들어오면 불려지고 각각 태깅이 된다. B값들은 entity 개수별로 불리면 w2v를 돌릴 수 있다.
Intent 와 NER 모델을 만들기 위한 Data의 구성 방법¶
- 피자주문, 숙소예약, 여행정보의 각각의 Entity구성 (서비스시에는 Entity는 별도 DB로 구성
- Entity 별 N by N의 수로 정제된 Text를 구할 수 있음
train_data_order = ['판교에 오늘 피자 주문해줘']
train_data_reserve = ['오늘 날짜에 호텔 예약 해줄레']
train_data_info = ['모래 날짜의 판교 여행 정보 알려줘']
get_data_list = train_data_info[0]
dict_entity = {
'date' : ['오늘','내일','모래'],
'loc' : ['판교','야탑'],
'menu' : ['피자','햄버거'],
'hotel' : ['호텔','여관','민박'],
'travel' : ['여행','관광','카페']
}
length = 1
for key in list(dict_entity.keys()):
length = length * len(dict_entity[key])
print("Augmentation length is {0}".format(length))
형태소 분석¶
from konlpy.tag import Mecab
mecab = Mecab('/usr/local/lib/mecab/dic/mecab-ko-dic')
morpphed_text = mecab.pos(get_data_list)
print(morpphed_text)
Feature Engineering (명사만 도출)¶
Feature Engineering으로 Intent와 NER의 정확도를 높임)
- 일반명사(NNG) [메뉴]
- 고유명사(NNP) [지역]
- 영어(SL) [Pizza]
- 시간부사(MAG) [오늘, 내일, 모래]
- 한국어 품사 태그 비교표 https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0
tagged_text = ''
for pos_tags in morpphed_text:
if (pos_tags[1] in ['NNG','MAG', 'NNP','SL'] and len(pos_tags[0]) > 1): #Check only Noun
feature_value = pos_tags[0]
tagged_text = tagged_text + pos_tags[0] + ' '
print(tagged_text)
Intent 학습 Data의 구성¶
- Intent 성능 향상을 위해 parse한 Text Data를 represent화 함
pattern = ''
for word in tagged_text.split(' '):
entity = list(filter(lambda key:word in dict_entity[key],list(dict_entity.keys())))
if(len(entity) > 0):
pattern = pattern + 'tag' + entity[0] + ' '
else:
pattern = pattern + word + ' '
print(pattern)
Data augmentation (Entity and Pattern)¶
- 각 의도별 Pattern text를 entity의 N 배수로 Augmenatation 작업
def augmentation_pattern(pattern, dict_entity):
#입력된 패턴을 List로 바꿈
aug_pattern = pattern.split(' ')
#Augment된 Text List
augmented_text_list = []
#copy를 위한 임시 List
temp_aug = []
for i in range(0,len(aug_pattern)):
#Entity에 해당하는 값일 경우 Entity List를 가져옴
if(aug_pattern[i].find("tag") > -1):
dict_list = dict_entity[aug_pattern[i].replace("tag","")]
#각 Entity별로 값을 append하면서 Pattern구성
for j in range(0,len(dict_list)):
#최초 Entity값은 그냥 추가만함
if(i == 0):
augmented_text_list.append(dict_list[j] + " ")
elif(j == 1):
augmented_text_list = list(filter(lambda word:len(word.split(' ')) == i + 1 ,augmented_text_list))
copy_data_order = augmented_text_list * (len(dict_list)-2)
augmented_text_list = list(map(lambda x:x + dict_list[j] + " ",augmented_text_list))
augmented_text_list = augmented_text_list + temp_aug + copy_data_order
else:
#List의 수를 체크하여 값을 추가
temp_aug = list(filter(lambda word:len(word.split(' ')) == i+1 ,augmented_text_list))
temp_aug = list(map(lambda x:x + dict_list[j] + " " ,temp_aug))
#추가된 List를 위해 기존 값 삭제
if(j != 0):
augmented_text_list = augmented_text_list[0:len(augmented_text_list) - len(temp_aug)]
augmented_text_list = augmented_text_list + temp_aug
#Entity추가 대상이 아닐 경우 Pattern만 추가
else:
augmented_text_list = list(map(lambda x:x + aug_pattern[i] + " ",augmented_text_list))
#N*N으로 증가시키기 위한 List
temp_aug = augmented_text_list
return augmented_text_list
augmented_text_list = augmentation_pattern(pattern, dict_entity)
augmented_text_list
BIO Tagging¶
def augmentation_bio_pattern(pattern, dict_entity):
#입력된 패턴을 List로 바꿈
aug_pattern = pattern.split(' ')
#Augment된 Text List
augmented_text_list = []
#copy를 위한 임시 List
temp_aug = []
for i in range(0,len(aug_pattern)):
#Entity에 해당하는 값일 경우 Entity List를 가져옴
if(aug_pattern[i].find("tag") > -1):
dict_list = dict_entity[aug_pattern[i].replace("tag","")]
bio_tag = aug_pattern[i].replace("tag","B_")
#각 Entity별로 값을 append하면서 Pattern구성
for j in range(0,len(dict_list)):
#최초 Entity값은 그냥 추가만함
if(i == 0):
augmented_text_list.append(bio_tag + " ")
elif(j == 1):
augmented_text_list = list(filter(lambda word:len(word.split(' ')) == i + 1 ,augmented_text_list))
copy_data_order = augmented_text_list * (len(dict_list)-2)
augmented_text_list = list(map(lambda x:x + bio_tag + " ",augmented_text_list))
augmented_text_list = augmented_text_list + temp_aug + copy_data_order
else:
#List의 수를 체크하여 값을 추가
temp_aug = list(filter(lambda word:len(word.split(' ')) == i+1 ,augmented_text_list))
temp_aug = list(map(lambda x:x + bio_tag + " " ,temp_aug))
#추가된 List를 위해 기존 값 삭제
if(j != 0):
augmented_text_list = augmented_text_list[0:len(augmented_text_list) - len(temp_aug)]
augmented_text_list = augmented_text_list + temp_aug
#Entity추가 대상이 아닐 경우 Pattern만 추가
else:
augmented_text_list = list(map(lambda x:x + aug_pattern[i] + " ",augmented_text_list))
#N*N으로 증가시키기 위한 List
temp_aug = augmented_text_list
return augmented_text_list
bio_list = augmentation_bio_pattern(pattern, dict_entity)
bio_list
NER을 위한 Full Train Text 확보¶
- tag entity를 NER 학습을 위한 Labeled Entity로 변환 (Bi-LSTM 학습을 위함)
ner_train_text = [augmented_text_list, bio_list]
ner_train_text
위에서 얻은 Data를 토데로 Intent와 NER의 모델을 얻기 위해 학습시킬 수 있음¶
'beginner > ChatBot' 카테고리의 다른 글
| Stanford CS230: Deep Learning | Autumn 2018 | Lecture 10 - Chatbots 강의 내용 정리 (0) | 2019.06.10 |
|---|---|
| Chatbot Development Challenges — Part 2 (1) | 2019.05.31 |
| Chatbot Development Challenges — Part 1 (3) | 2019.05.31 |
| Python과 Tensorflow를 활용한 Al 챗봇 개발 4강 (1) | 2019.05.27 |